Business Problem.
The law requires that businesses identify whether a potential client is a politically exposed person (PEP) in order to prevent corruption.
Different definitions exist between countries, but generally speaking, a PEP is a person who is or has been entrusted with prominent public functions in a country or interational organistion.
When I set up Know Your Sanctions, a sanctions and PEP screening platform, I wanted users to both identify political actors and understand their financial interests where possible.
Gathering and enriching PEP data with data about their financial interests proved possible in the UK, and here is how I did it with Python.
Collect PEP data
Request data with UK Parliament's API
When gathering data on politically exposed persons, a good place to start is always the country's legislative assembly. Lucky me, Parliament has an API that makes gathering basic data on members of the House of Commons and the House of Lords easier.
I know from the documentation that there are 1400 entries and set up my parameters:
base_url = 'https://members-api.parliament.uk/api/Members/Search'
skip = 0
take = 20
total_entries = 1400
all_members = []
We gather our data in a a while statement that sends an API request until all 1400 entries have been collected.
If we recieve a valid response, we save the data from each json response to my members varaible that is then appended to my all_members list. Skip is then updated for the next request so that we know when we reach our last request.
while skip < total_entries:
# Make a request to the API with the current skip value
url = f'{base_url}?skip={skip}&take={take}'
response = requests.get(url)
if response.status_code == 200:
try:
data = response.json()
members = data['items']
# Append the retrieved members to the list
all_members.extend(members)
# Update the skip value for the next request
skip += take
except (json.JSONDecodeError, KeyError) as e:
print("Error parsing JSON:", str(e))
break
else:
print("Error fetching data. Status code:", response.status_code)
break
Extract the Data
Our data is now stored in our all_members list. This list is a list of dictionaries.
[{'value': {'id': 172, 'nameListAs': 'Abbott, Ms Diane', 'nameDisplayAs': 'Ms Diane Abbott', 'nameFullTitle': 'Rt Hon Diane Abbott MP', 'nameAddressAs': 'Ms Abbott', 'latestParty': {'id': 8, 'name': 'Independent', 'abbreviation': 'Ind', 'backgroundColour': 'C0C0C0', 'foregroundColour': 'FFFFFF', 'isLordsMainParty': False, 'isLordsSpiritualParty': False, 'governmentType': None, 'isIndependentParty': True}, {'rel': 'contactInformation', 'href': '/Members/331/Contact', 'method': 'GET'}]}, {'value': {'id': 1615, 'nameListAs': 'Barnes, Michael', 'nameDisplayAs': 'Michael Barnes', 'nameFullTitle': 'Michael Barnes', 'nameAddressAs': None, 'latestParty': {'id': 15, 'name': 'Labour', 'abbreviation': 'Lab', 'backgroundColour': 'ff0000', 'foregroundColour': 'ffffff', 'isLordsMainParty': True, 'isLordsSpiritualParty': False, 'governmentType': 3, 'isIndependentParty': False}, 'gender': 'M', 'latestHouseMembership': {'membershipFrom': 'Brentford and Chiswick', 'membershipFromId': 430, 'house': 1, 'membershipStartDate': '1966-03-31T00:00:00', 'membershipEndDate': '1974-02-28T00:00:00', 'membershipEndReason': None, 'membershipEndReasonNotes': None, 'membershipEndReasonId': None, 'membershipStatus': None}, 'thumbnailUrl': 'https://members-api.parliament.uk/api/Members/1615/Thumbnail'}, 'links': [{'rel': 'self', 'href': '/Members/1615', 'method': 'GET'}, {'rel': 'overview', 'href': '/Members/1615', 'method': 'GET'}, {'rel': 'synopsis', 'href': '/Members/1615/Synopsis', 'method': 'GET'}, {'rel': 'contactInformation', 'href': '/Members/1615/Contact', 'method': 'GET'}]},
We extract the data for each member by looping over the list of dictionaries and appending the item to each list. If no item is found, we'll simply append an empty string.
# Extracting data for each member
for member in all_members:
try:
id.append(member['value']['id'])
except:
id.append('')
...etc
Now that we have each parliamentarian's data, we can create a data frame and save the result in a csv.
df = pd.DataFrame({
'entity_id': id,
"Name": names,
"Party": parties,
"Membership": memberships,
"start_date": start_dates,
"end_date": end_dates,
"active": statuses,
'status_description': status_description,
'house': house
})
df.to_csv('./UK Parliament/parliamentarians.csv')
Enrich PEP data
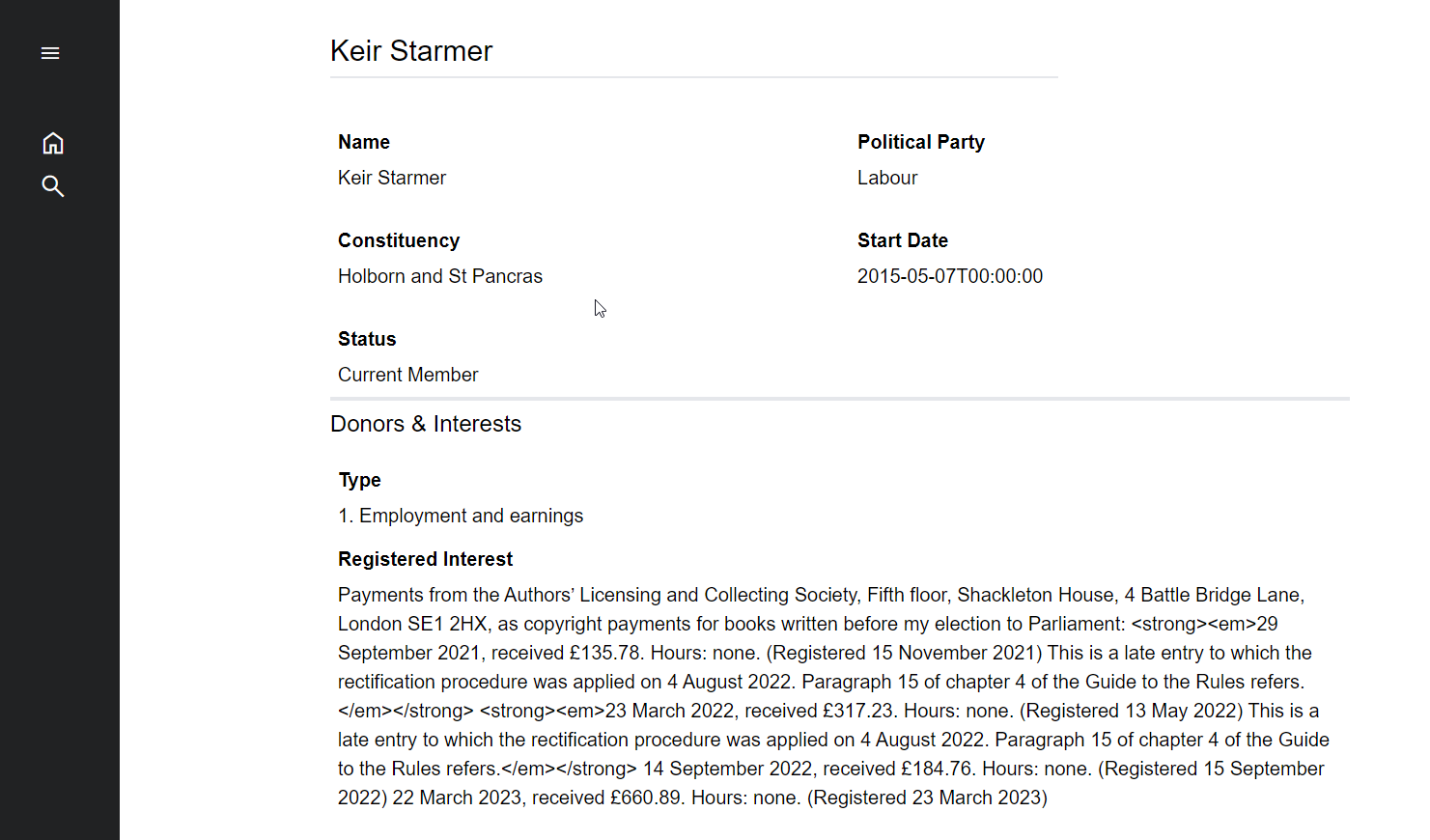
The Register of Members Financial Interest
Details about the financial interests of Members of the House of Commons and the House of Lords is available as a csv on Members Interest. What's great about Members Interest is that they have indexed the Register of Members Financial Interests.
The main purpose of the Register is to provide information about any financial interest which a Member has, or any benefit which he or she receives, which others might reasonably consider to influence his or her actions or words as a Member of Parliament.
Why use the Register of Members Financial Interest?
The Register of Members Financial Interest is really useful and contains:
- Who donors are and how much they donated
- The Employment and earnings of peers
- Visits outside the UK made by peers, to whom they travelled, where they stayed, costs and the purpose of their visit
- Miscellaneous data on gifts and hospitality
With these data points, we can work out the habits and connections of our politically exposed person. It tells us about their employment, salary, who they worked for, where they've been, who donates to whom and why and why our MPs go abroad.
What's great is that the register is updated every 28 days and it goes back many years, meaning we have a good understanding of the different interests that our peers have.
How to enrich our PEP data?
Since the financial interest data comes as a csv, all we need to do is download the csv and merge the data with our file on MPs and Lords in order to enrich our PEP profiles.